수리과학, 물리학, 화학, 생명과학 분야와 이들을 기반으로 한 융&복합 분야
미래 산업 경쟁력 강화의 근간이 되는 소재 및 ICT 분야
과제 & 연구자
과제 & 연구자
큰 꿈을 향한 무한탐구의 연구열정,
삼성미래기술육성사업이 응원하며 함께 하겠습니다.

Mobile-SpecInfer: 모바일 시스템용 생성형 언어모델의 Speculative 추론 가속
최근 인공지능 기술의 발전이 다양한 산업 분야에 혁신을 가져왔습니다. 특히, 생성형 대형언어모델(LLM)은 자연어 처리 분야에서 중요한 역할을 하고 있습니다. 그러나 LLM은 자동회귀(autoregressive) 방식으로 토큰을 생성하면서 병렬성과 연산 강도(arithmetic intensity)가 낮은 GEMV(matrix-vector 곱) 연산을 수행해야 하므로, NPU와 같은 가속기의 연산 능력을 충분히 활용하지 못하는 문제가 있습니다.
이 문제를 해결하기 위해 최근에는 원래의 큰 대상 모델(LTM: Large Target Model)보다 작은 Speculative 모델들(SSM: Small Speculative Model)을 도입하여 후보 토큰들을 신속하게 생성하고, 이를 LTM에서 병렬로 디코딩하여 검증하는 Speculative Inference(SpecInfer) 기술이 개발되어 서버 GPU에서의 전체 추론 시간을 2~3배까지 단축할 수 있게 합니다.
한편 최근 온-디바이스 AI 응용이 확산됨에 따라 모바일 장치에서의 LLM 실행에 대한 요구가 증가하고 있습니다. LLM은 대용량 파라메터로 인해 매우 큰 메모리 용량과 연산량을 요구하므로 자원에 제약이 있는 모바일 장치에서 실행하기가 쉽지 않습니다. 이를 해결하기 위해 파라메터의 양자화와 가지치기(Pruning) 등의 모델 압축 기법이 제안되었으나, 이러한 방법들은 종종 정확도 저하를 초래하며, 압축된 모델의 추론 시 하드웨어 지원을 필요로 합니다. SpecInfer 기법은 모바일 시스템에서 NPU의 활용도를 높임으로써 성능을 향상시킬 수 있는 유망한 대안이 될 수 있습니다. 그러나 이 기법은 메모리 부족 문제는 해결하지 못하며, 현재로서는 모바일 장치에서의 SpecInfer를 위한 추론 엔진 지원 또한 부족한 상황입니다.
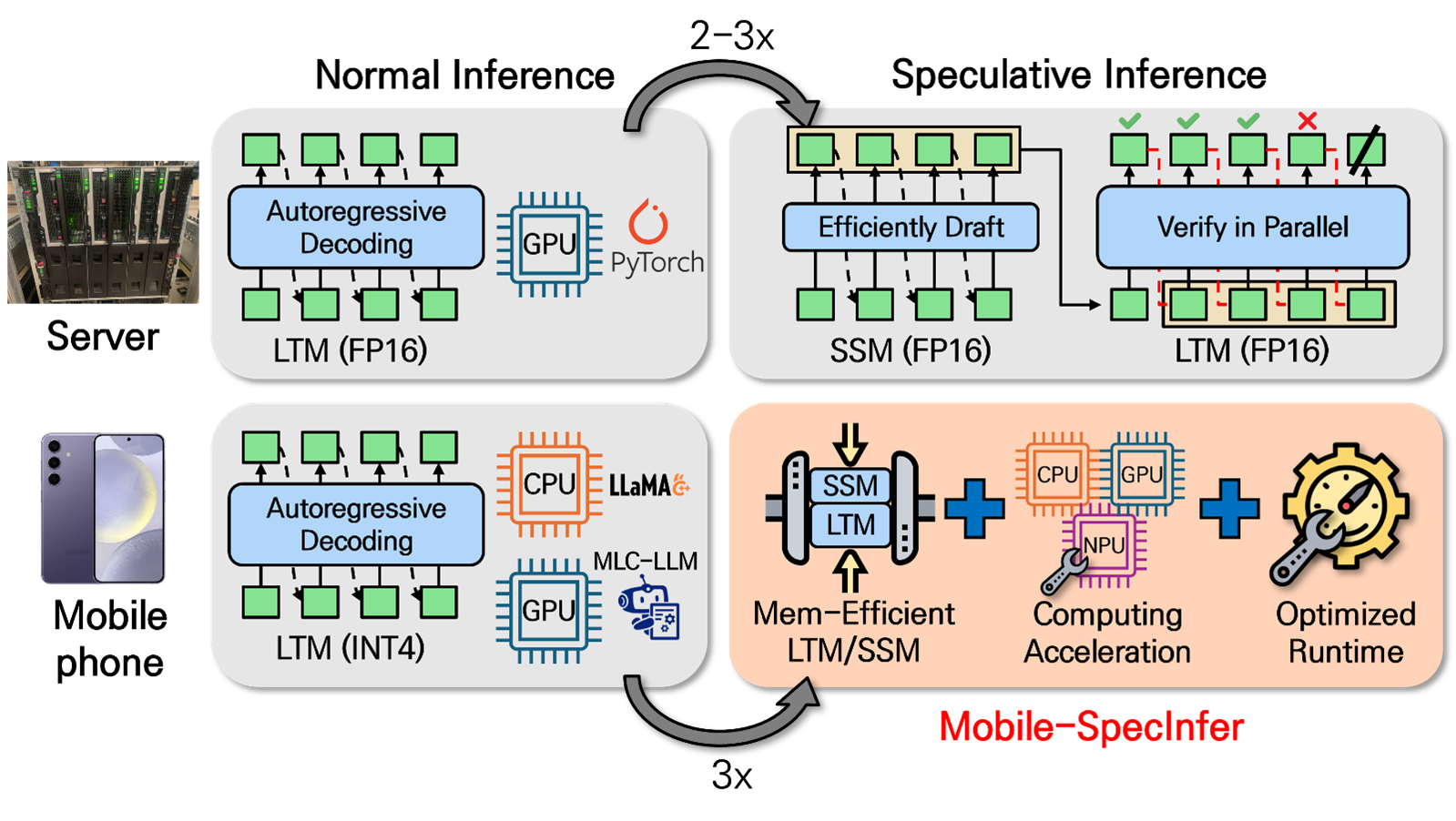
그림 1. 모바일 기기에서 효과적인 온-디바이스 LLM 추론을 위한 Mobile-SpecInfer 개요
본 연구는 모바일 기기의 제한된 자원을 고려한 SpecInfer 기법인 Mobile-SpecInfer를 연구하여 모바일 시스템에서 고속의 온-디바이스 LLM 추론을 가능하게 하고자 합니다. 기존 연구와 대비하여 본 연구는 다음과 같은 세 가지 주요 차별성을 갖습니다. 첫째, SpecInfer 기법에 적합한 모델 압축 기술과 메모리 절감 기술을 개발하여, 모바일 장치의 제한된 메모리와 연산 장치에서 SpecInfer 사용을 가능하게 합니다. 둘째, SpecInfer의 특성에 맞는 LLM 추론 엔진을 설계합니다. 셋째, 모바일 시스템의 CPU/GPU/NPU를 활용한 SpecInfer 추론 가속 기법을 연구합니다.
본 연구는 서버 GPU에서 집중되어 온 LLM의 Speculative Inference 기술을 모바일 시스템에 처음으로 적용하는 연구가 됩니다. 이 과정에서 Speculative Inference를 위한 다양한 모델 압축 기법, 모바일용 추론 엔진, NPU 아키텍처 등 소프트웨어와 하드웨어를 아우르는 다양한 최적화 연구를 수행하며, 이러한 기술적 진보가 온-디바이스 LLM을 활용한 다양한 산업 기술 발전에 기여할 수 있을 것으로 기대합니다.
최근 인공지능 기술의 발전이 다양한 산업 분야에 혁신을 가져왔습니다. 특히, 생성형 대형언어모델(LLM)은 자연어 처리 분야에서 중요한 역할을 하고 있습니다. 그러나 LLM은 자동회귀(autoregressive) 방식으로 토큰을 생성하면서 병렬성과 연산 강도(arithmetic intensity)가 낮은 GEMV(matrix-vector 곱) 연산을 수행해야 하므로, NPU와 같은 가속기의 연산 능력을 충분히 활용하지 못하는 문제가 있습니다. 이 문제를 해결하기 위해 최근에는 원래의 큰 대상 모델(LTM: Large Target Model)보다 작은 Speculative 모델들(SSM: Small Speculative Model)을 도입하여 후보 토큰들을 신속하게 생성하고, 이를 LTM에서 병렬로 디코딩하여 검증하는 Speculative Inference(SpecInfer